The first release of GUM series 5 in 2019 brings several new features to our multilayer corpus - this post outlines the most important additions.
What is GUM?
GUM is an open source multilayer corpus of richly annotated web texts from eight text types. The corpus is collected and expanded by students as part of the curriculum in LING-367 Computational Corpus Linguistics at Georgetown University. The selection of text types is meant to represent different communicative purposes, while coming from sources that are readily and openly available (mostly Creative Commons licenses), so that new texts can be annotated and published with ease.
New data
After a second year of collecting data from four new genres, the corpus is now bigger than ever, and is gradually becoming more balanced:
| text type | source | texts | tokens |
|---|
| Interviews | Wikinews | 19 | 18,037 |
| News stories | Wikinews | 21 | 14,093 |
| Travel guides | Wikivoyage | 17 | 14,955 |
| How-to guides | wikiHow | 19 | 16,920 |
| Academic writing | Various | 12 | 10,966 |
| Biographies | Wikipedia | 13 | 11,562 |
| Fiction | Various | 13 | 12,082 |
| Forum discussions | reddit | 12 | 10,526 |
| Total | | 126 | 109,141 |
This year saw the biggest growth in fiction texts, which can be very challenging to annotate for discourse structure due to possible differences in the communicative functions expressed by the narrator versus discourse motivations found embedded in direct speech.
Sorting out other sentences
Our sentence type annotations, which categorize utterances into rough speech act types (declaratives, questions, imperatives...) often didnt match any one prototype, and were given the label other. having a label like other is generally just a last resort, but is often useful for identifying unusual cases and refining the annotation scheme later on; in 2018 we did just that and distinguished cases where multiple sentence types are coordinated by 'and' etc. We now label these with the type multiple vs. truly unusual types, which remain labeled as other.
You can find examples of these types of sentences in our online search interface, ANNIS:
Reworking the bridging annotations and visualization
Bridging is a special case of discourse anaphora, where an entity is introduced as already familiar to the reader/hearer based on the mention of a different previously mentioned entity. Annotating bridging helps us to research how definite expressions can be introduced without previous mention, over semantic links such as part-whole - here's an example from GUM:
The games
have features like increasing challenges, rules that establish what can and can not be done, and involvement of the player
in the quest to gain skills
(games imply → player)
[Open in ANNIS]
Our bridging annotations used to be mixed with our coreference annotations, but starting in 2019 we separated them in our datamodel and they can now be viewed separately:
Separate coreference and bridging visualizations of the same text. Spans with the same color highlighting are connected via a coreference relation (left) or a bridging relation (right).
We are also starting to categorize cases of bridging into multiple subclasses, though this process is in preliminary stages. Unlike version 4 of GUM, which lumped together all kinds of non-strict coreference, the current release of the corpus distinguishes:
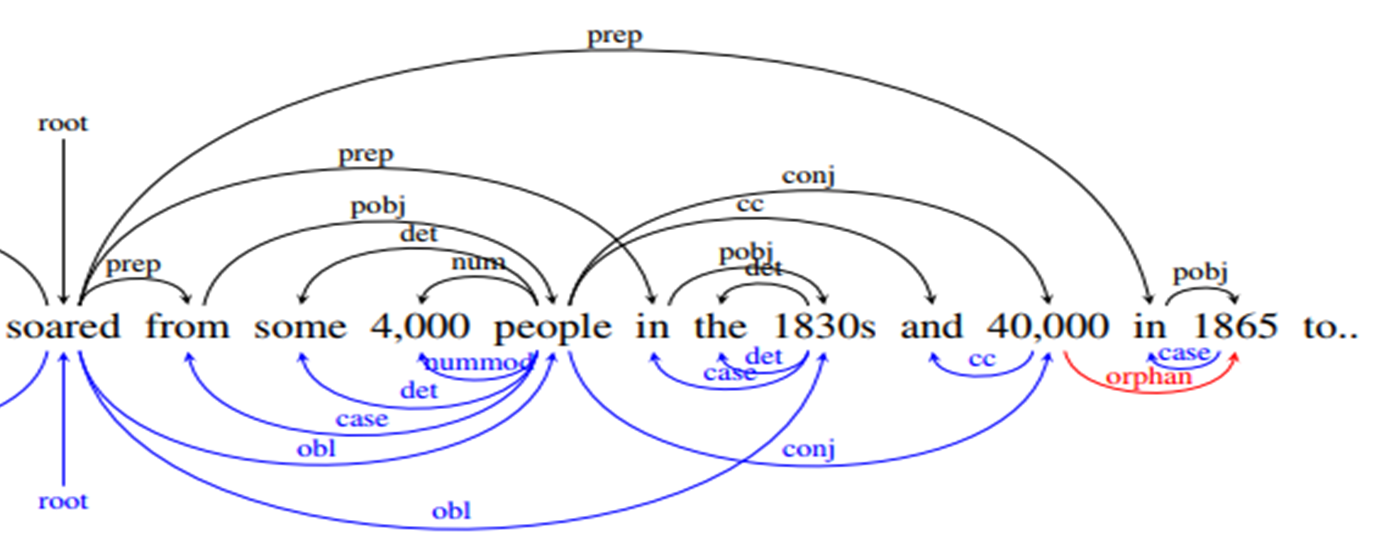
Multiple dependency trees in ANNIS
GUM syntax annotations started out using the Stanford Typed Dependencies scheme, but after the release of Universal Dependencies (UD), we started releasing an automatically converted UD
version which takes advantage of other annotation layers to disambiguate trees and prevent errors. In this paper we showed that this conversion strategy is almost error free, in part thanks to the amount of information available in the multilayer corpus.
Automatic multilayer conversion of Stanford Dependencies to Universal Dependencies from Peng & Zeldes (2018).
In the latest GUM release, both types of dependencies, as well as constituent annotations and universal morphological features can be searched concurrently. You can see these visualizations directly in ANNIS:
Stanford Dependencies
Universal Dependencies