

Annotations
Individual annotation layer documentation
The GUM corpus contains a large number of concurrent annotations which can be grouped into 'layers'. Each layer is structurally independant of other layers, and often created using different tools and at different times, though the build-bot used to correct the corpus (see Corrections) enforces some consistency between layers (for example: constituent syntax and dependency syntax layers use the same sentence boundaries). The following layers are currently included in the corpus:
- tok - multiple parts of speech, segmentation and lemmatization for each token
- tei - document structure, links, ISO date/time, sentence types, errors and more
- const - Penn Treebank-style trees, including phrase function labels
- dep - Universal Dependencies (UD) trees
- edep - Enhanced dependency graphs
- morph - morphological categories based on the UD inventory
- ref - nested, named and non-named entity types, coreference, information status and Wikification
- bridge - bridging anaphora and split antecedent coreference
- rst - discourse parses in Rhetorical Structure Theory++
- rsd - dependency version of discourse annotations
- meta - metadata and document level annotations
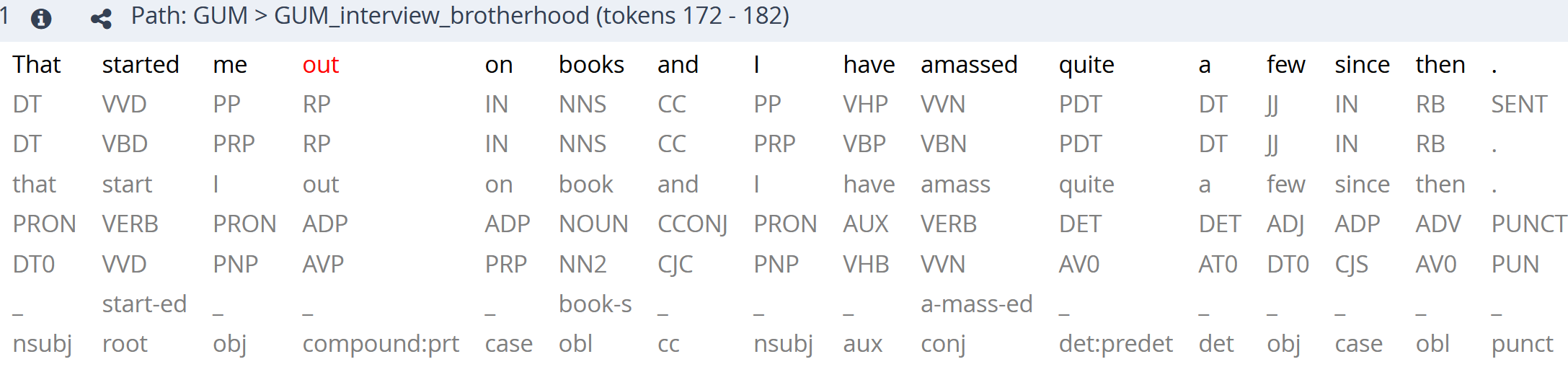
tok - token annotations
Each token in the GUM corpus is manually checked for correct segmentation, manually tagged using the Penn Tagset with TreeTagger extensions (e.g. distinguishing lexical verbs as VV* from auxiliaries VB* and VH*; see here for details, and the original PTB tagging guidelines without extended tags here). The tokens are automatically lemmatized using Stanza and manually corrected, and a second automatic part of speech tag using the CLAWS5 tag set is added, as well as original Penn Treebank tags. This phase of the annotation is done using the GitDox annotation interface.
| pos | part of speech tags in the Penn/TreeTagger tag set |
| xpos | part of speech tags in the original Penn Treebank tag set |
| upos | Google universal part of speech tags |
| claws5 | alternate part of speech tag using the CLAWS5 tag set |
| lemma | lemma (dictionary entry) for each token |
| mseg | morphological segmentation (e.g. un-believ-able) |
| tok_func | convenience annotation giving the token's dependency function |
tei - text encoding initiative
The tei layer contains a variety of information relating to document structure and appearance, following the TEI p5 guidelines. Most annotations relate to formatting, but some relate to contents (e.g. date annotations) and coarse linguistic features (e.g. basic sentence spans, and non-normative/erroneous language using the <sic> tag and the @ana attribute with a corrected target hypothesis). The following list of annotations gives an overview and some notes, and guidelines can be found here:
| caption | caption for images in the text |
| cell | a table cell |
| date | date expressions |
| date_from | starting date for a range of dates |
| date_notAfter | latest possible date for an inexact date |
| date_notBefore | earliest possible date for an inexact date |
| date_rend | formatting of a date expression (e.g. italics, color) |
| date_to | end date for a range of dates |
| date_when | date in question, normalized to the format yyyy-mm-dd |
| figure | marks the position of a figure in the text |
| figure_rend | a description of the appearance of the figure |
| foreign_xml_lang | ISO code for language of non-English words |
| gap | a gap in the text (e.g. ellipsis marked by an editor) |
| gap_reason | reason for a gap (e.g. 'omitted') |
| head | marks a heading |
| head_rend | a description of the appearance of the heading (e.g. bold) |
| hi_rend | a highlighted section with a description of its appearance (e.g. color) |
| incident_who | an extralinguistic incident (e.g. coughing), and the person responsible |
| item | item or bullet point in a list |
| item_n | item number |
| l_n | a line in poetry with its number |
| lg_n | a line group with the group's number |
| lg_type | line group type (e.g. stanza) |
| list | list of bullet points |
| list_type | a list type (e.g. bulleted, ordered, etc.) |
| note | a footnote or endnote |
| note_n | the number of a footnote |
| note_place | location of the note, e.g. 'foot' |
| p | a paragraph |
| p_rend | a description of the appearance of the paragraph |
| quote | a quotation |
| ref | an external reference, usually a hyperlink |
| ref_target | the target of the reference (usually a URL, if not ommitted) |
| row | a table row |
| s | a main sentence span |
| s_type | the sentence mood / rough speech act (declarative, subjunctive, imperative, question..) |
| sic | a section containing an apparent language error, thus in the original |
| sic_ana | a corresponding reconstructed target hypothesis in standard English |
| sp_who | a section uttered by a particular speaker with a reference to the speaker |
| sp_whom | a section uttered with a particular speaker as an addressee |
| table | a table containing the text |
| table_cols | number of columns in a table |
| table_rend | rendering information for a table, e.g. 'boxed' |
| table_rows | number of rows in a table |
| w | a fused word form encompassing more than one token (e.g. can|not) |

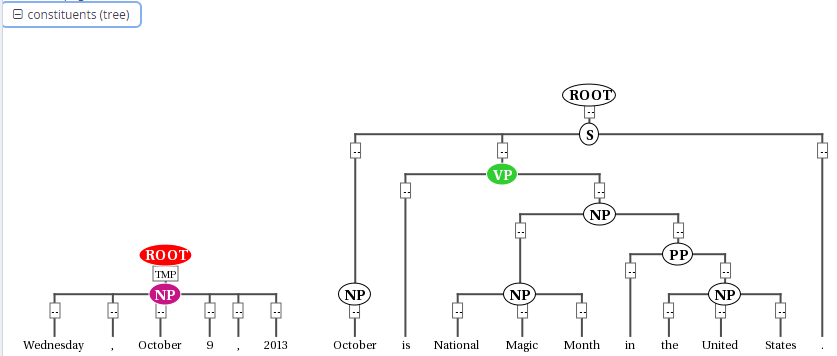
const - constituent trees
The const layer contains constituent syntax trees, with some function labels included on edges between constituents. This layer was produced using the Neural Adobe-UCSD Parser based on the gold POS tags, and aside from 8 test documents has not been fully corrected yet. Function labels for the constituents, such as "NP-SBJ" have been added automatically using a projection algorithm relying on the gold standard syntactic dependency labels from the dep layer.
| cat | syntactic category of the phrase (e.g. cat="NP") |
| func | grammatical function with respect to parent (e.g. cat >[func="MNR"] cat for manner adverbial modifier phrases) |
dep - dependency trees
The dep layer gives a dependency syntax analysis according to Universal Dependencies. This layer is initially produced using Stanza operating on gold tokens and POS tags, and is then manually corrected using the Arborator collaborative syntax annotation software. We follow general UD guidelines, and specific instructions for constructions found in our data are documented in our guidelines.
| dep | a dependency relation between two tokens |
| func | the universal dependency function according to the UD guidelines |
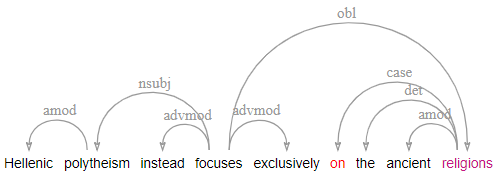
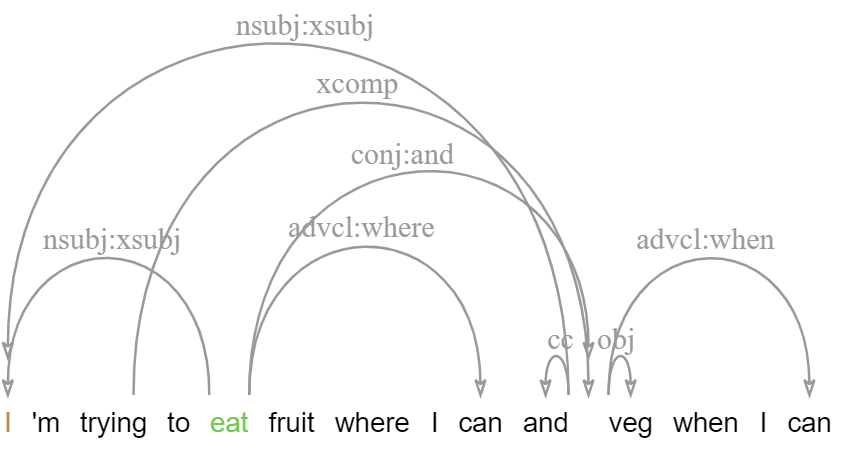
edep - enhanced dependencies
The edep layer adds an enhanced graph representation with structure sharing, which more closely reflects semantic argument structure (see the guidelines). This layer is produced semi-automatically by propagating structure sharing across coordination, subject and object control and more, and is then adjusted including the introduction of 'virtual' tokens to cover ellipsis, gapping, right-node-raising and related phenomena. This layer also provides augmented label types including lexical subtypes, such as obl:on to indicate an oblique PP modifier headed by 'on', or conj:or to indicate a disjunction marked by 'or'.
| edep | an enhanced dependency edge between two tokens (incl. multiple edges per token) |
| func | the enhanced dependency function according to the UD guidelines |
| Ellipsis | a virtual token node representing an elided token with an argument structure role |

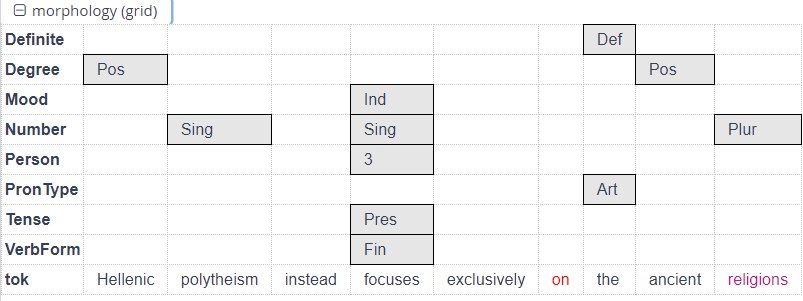
morph - universal morphological features
the morph layer represents basic inflectional categories, such as Person, Number, Tense, Mood and more. It is produced using a DepEdit script from the gold parses of the data, and follows Universal Dependencies standards.
| Abbr | abbreviation, "Yes" |
| Definite | definiteness, e.g. "Def" |
| Degree | adjective/adverb degree, e.g. "Sup" for superlative |
| Gender | grammatical gender, e.g. "Fem" |
| Mood | grammatical mood, e.g. "Ind" |
| Number | grammatical number, e.g. "Sing" |
| NumForm | orthographic form, e.g. "Roman" |
| NumType | type of number, e.g. "Card" |
| Person | grammatical person, e.g. "3" |
| Polarity | negative polarity, "Neg" |
| Poss | possessiveness, "Yes" |
| PronType | pronoun type, e.g. "Prs" |
| Reflex | reflexivity, "Yes" |
| Tense | grammatical tense, e.g. "Past" |
| VerbForm | verb form, e.g. "Fin" |
| Cxn | hierarchical Construction Grammar label, e.g. "Condition-Unrealistic-Inverted" |
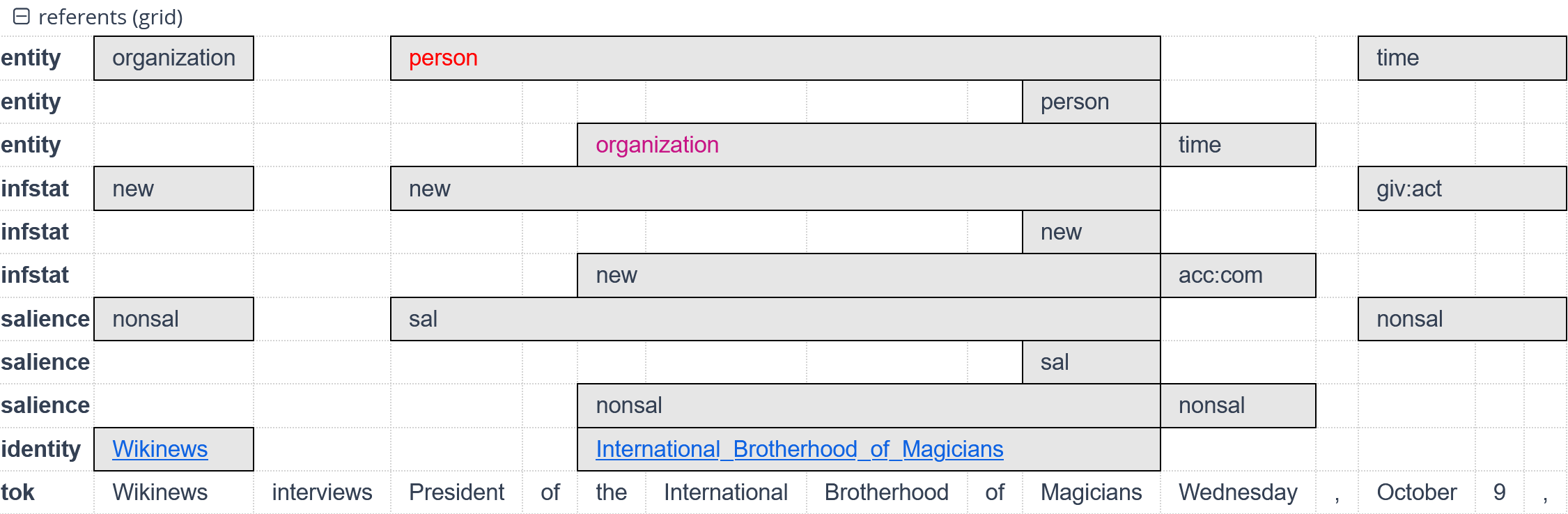
ref - discourse referents and coreference
The ref layer contains information about discourse referents, including their information structural information status (discourse new, given:active, given:inactive, accessible:inferrable, accessible:commonground, and accessible:aggregate for split antecedents), salience (salient or non-salient), and the type of entity they represent (a subset of the OntoNotes scheme including person, object, abstract, and more; see guidelines). Named entities, including their pronominal and non-named mentions, are also linked to their Wikipedia identifier provided they have a Wikipedia article. The ref layer also includes typed coreference edges between mentions of entities (including nested, non-named and pronominal mentions), distinguishing ana[phora], cata[phora], appos[ition] and other types of coref[erence]. All annotations are reviewed manually and corrected in the GitDox interface's Spannotator extension.
| entity | entity type |
| identity | Wikification identifier |
| infstat | information status (giv[en]-act/inact, acc[essible]:inf/com/aggr, or new) |
| salience | whether the mention belongs to a salient entity (only in .tsv format; see metadata in conllu) |
| coref | a coreference edge (AQL: entity ->coref entity) |
| type | coreference edge type annotation (ana[phora], cata[phora], appos[ition], disc[ourse], pred[ication], coref[erence]) |

bridge - bridging relations
The bridge layer contains information about discourse referents which are introduced indirectly through a previous mention of a different entity, which would lead one to anticipate the existence of the novel but accessible entity (see guidelines). These include aggr[egate] mention (i.e. split antecedent, joining previously separately mentioned entities as 'they'), def[inite] anaphoric bridging (e.g. whole + definite part in "a car ... the wheels", or 'other' types of bridging)
| bridge | a bridging edge (AQL: entity ->bridge entity) |
| type | bridging edge type annotation (bridge:aggr[egate], bridge:def[inite], bridge:other) |

rst - rhetorical structure
The rst layer provides an analysis of the text in eRST, an enhanced version of Rhetorical Structure Theory, using a set of 32 rhetorical relations, arranged at two hierarchical levels. Each segment of the text, which may be a sentence, clause or other unit, is integrated into a tree of utterances forming the rhetorical structure of the document. Segmentation guidelines are identical to the guidelines for the RST Discourse Treebank, and structuring and discourse relation guidelines can be found here. Trees are augmented with tree-breaking secondary edges where needed, and relations point to categorized signals indicating how the relations may be recognized based on properties of the text, including via discourse markers (connectives like 'but' or 'because'), punctuation, morphology, layout, coreference and other means. Analyses are created using rstWeb.
| (node) kind | for dominating structures (single segment span or group of segments) |
| (node) type | for group structures (simple span or multinuc) |
| (edge) type | rst edge type (rst relation or multinuc relation) |
| (edge) end | distinguishes 'source' and 'target' nodes for tree-breaking secondary edges |
| relname | rst relation name (elaboration-additional, explanation-evidence, etc.; see guidelines) |
| signal_type | a major signaling device type, e.g. 'dm', 'syntactic', 'semantic' etc. |
| signal_subtype | a signal subtype such as 'reported_speech' (syntactic), 'indicative_phrase' (lexical), etc. |
| signal_text | text in the span of a signal. |
| signaled_relation | the relation type belonging to the signal. |
| (edge) signal_token | the relation between a signaled relation and the signaling token |
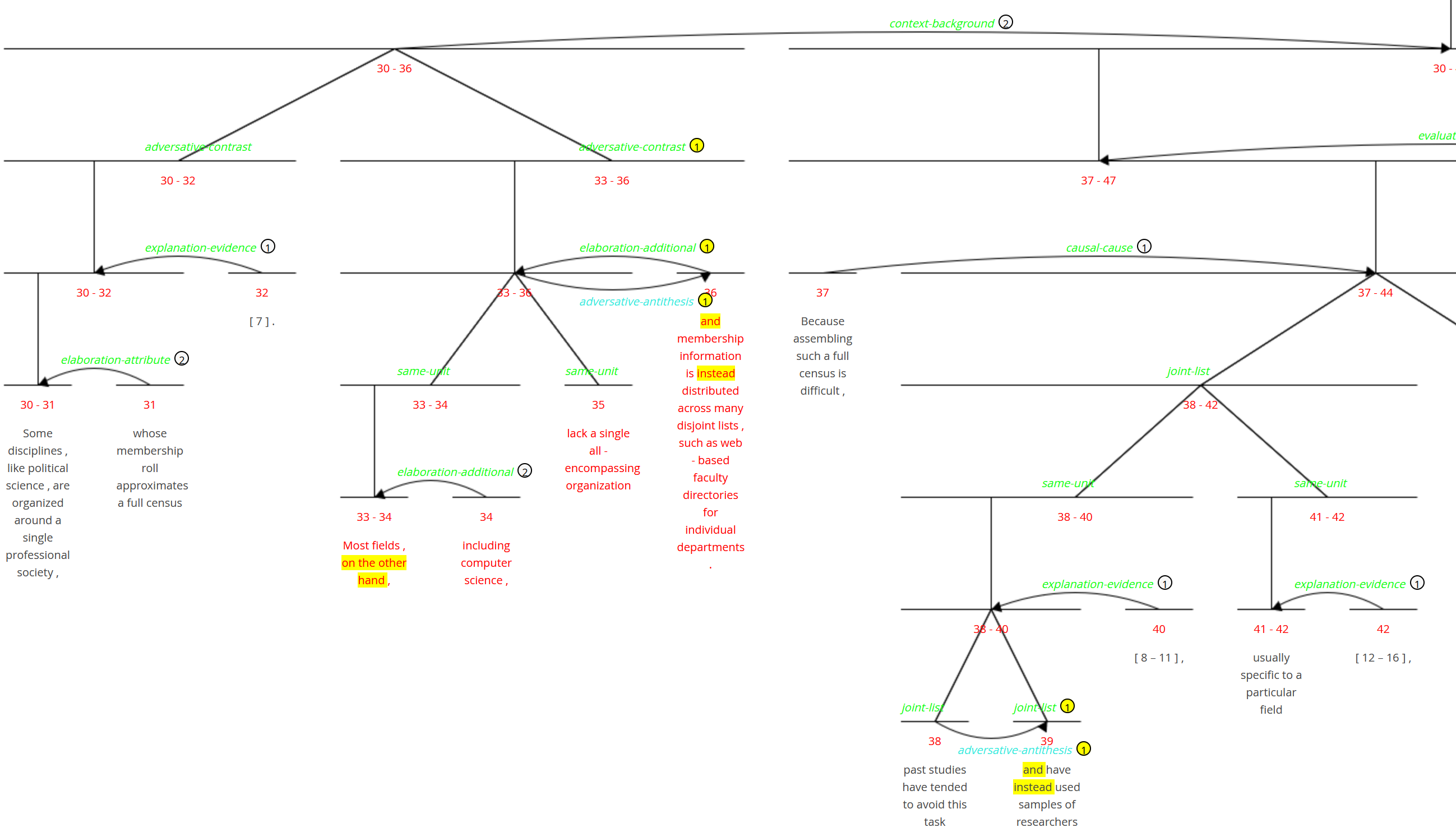
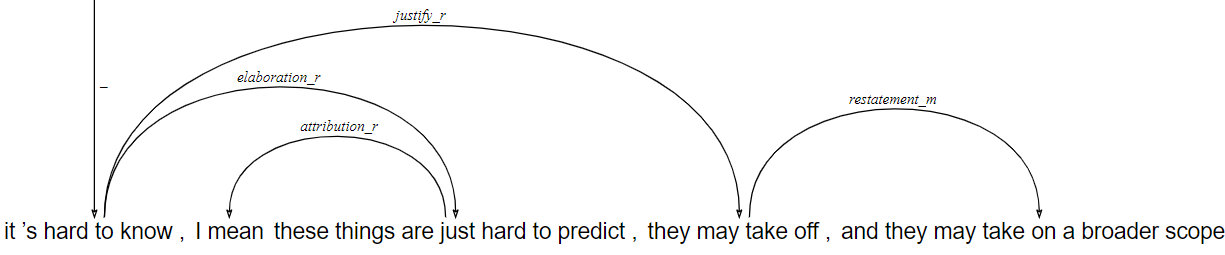
rsd - rhetorical structure dependencies
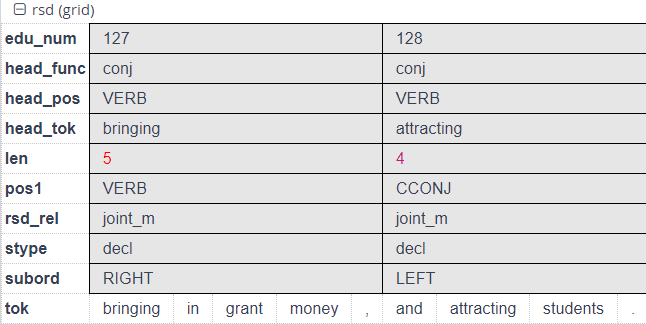
The rsd layer gives a dependency conversion of the RST layer, using only the discourse segments and no non-terminal grouping spans or coordinate structures. Discourse units are enriched automatically with a number of annotations.
| rsd_rel | the discourse relation that the span heads |
| head_func | root syntactic dependency function of the span |
| head_pos | root UPOS tag of the span |
| head_tok | root word form of the span |
| len | span length in tokens |
| pos1 | first UPOS tag in the span |
| stype | the sentence type containing the span |
| subord | the direction of syntactic subordination of the span (LEFT, RIGHT or NONE) |
| func | dependency relation name as an edge annotation, ends in _m for multinuclear relations, _r otherwise |
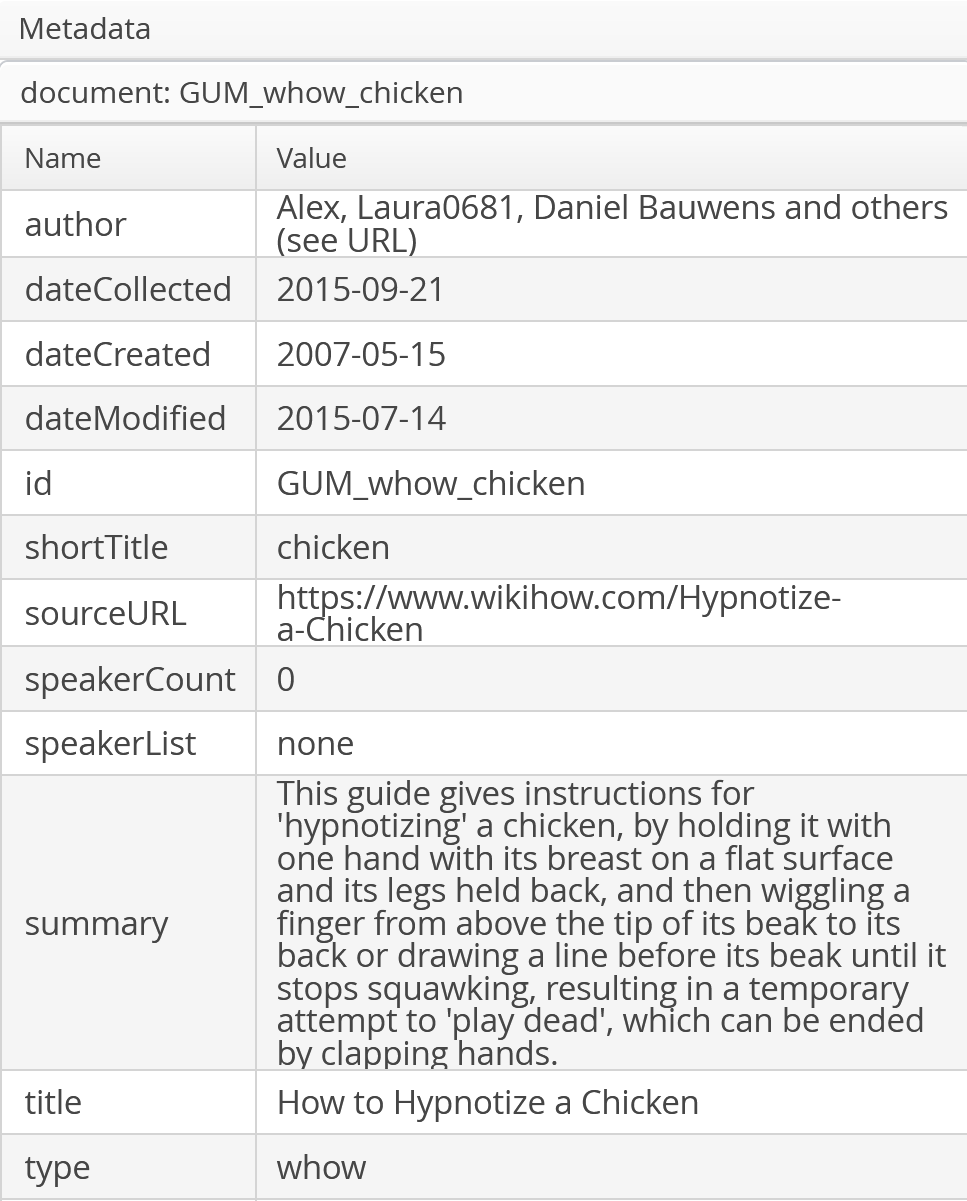
meta - metadata and document level annotations
Each document has metadata indicating provenance, document creation time and speaker information, as well as document level annotations, such as a one sentence summary of the text constructed according to the guidelines.
| author | document author(s) or other appropriate attribution source |
| dateCollected | date when contents were collected from the source |
| dateCreated | earliest known date when the source existed |
| dateModified | date of the last known modification of the source data before collection |
| salientEntities | a comma separated list of unique CoNLL-U IDs for the most salient entities in the document |
| shortTitle | a unique one-word title representing the document |
| sourceURL | link to the document's original location |
| speakerCount | number of speakers (0 for a written text with no speakers) |
| speakerList | list of speaker IDs used in the annotation (or 'none' if 0 speakers) |
| summary | a one sentence summary according to the guidelines |
| title | original title at the source of the document (full article title, video title etc.) |
| type | GUM text type or genre (bio, news, vlog etc.) |